三部形式。長い階段を登っていくかのような、あるいは人生の苦悩をつづるかのようなテーマで始まる。
中間部は左手で流れるような16分音符が奏され、夢の中のような、あるいは暖かな風が吹いているかのような場面となる。
最初のテーマが繰り返される。
最初のテーマが右手に現れつつ、左手には中間部の流れる音型が組み合わされるという興味深い展開が現れて終わる。
楽譜引用はヘンレ版から。
Apple Musicの方はこちら。
ここに来て、第2楽章に緩徐楽章を配置する3楽章制の古典的なソナタに回帰する。
第1楽章は主題の音型から「かっこう」と呼ばれることがある。
第1楽章は全体に明るいテーマで構成される。
展開部は転調するが長調のまま。
かっこうのテーマが展開される。
転調を織り交ぜるが、大きな発展は無くかっこうのテーマが繰り返される。
再現部。
展開部と再現部は繰り返しとなっている。
再現部の後に終わりを告げるパートがあり、左手で最初のテーマが奏される。
楽譜引用はヘンレ版から。
Apple Musicの方はこちら。
第12番の終楽章、第22番の終楽章と、このような調性の薄い高速な楽章がたまに現れる。
1つ目のテーマは、符点を主体としたもの。
もう1つは、16分音符2つがスラーでつながった音型。この2つが自由に展開される。
この音型が曲全体で繰り返し使用される。
曲は自由な構成だが、この音型が何度も使用されるため、不思議なまとまりを感じさせる。
楽譜引用はヘンレ版から。
Apple Musicの方はこちら。
前回の「冬休みの自由研究でOCRを作ってみた」では、最後の認識にMNISTを学習データとして使ったので、あまり精度が良くなかった。そこで、認識の部分にOSSのOCRであるtesseractを使用することで、再度検証してみることにした。tesseractには、-psmというパラメータで認識方法を指定できる。
Page segmentation modes:
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR.
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
10を指定すれば、1つの文字として認識を行うことができる。もちろん、tesseractがあるなら、そのままOCRとして使えばいいわけで実用性あるの? という話になるが、tesseractは、特定の苦手なシーンがあり、今回の方法でそれが克服できないかを検証することが目的だ。合わせて、手軽に使えるOCRの中では個人的には一番精度が高いと評価している、Google Cloud Visionとの比較もしてみることにする。Google Cloud Visionは、このサイトで簡単に試してみることが可能だ。
今回は、こういう画像を使用。tesseractは二値化されていないと精度が著しく落ちるので、予め二値化してある。
Google Cloud Vision使ってみると、きちんと認識されている。さすがだ。
今回のOCRは数字が等幅フォントで1行で書かれたものを処理対象とするため、ここから切り出してから処理する。
まずは、普通に切り出したものを処理してみる。tesseractというオプション指定を追加して、分解した文字をtesseract -psm 10で1文字ずつ認識するようにしてみた。
$ docker run -it --rm -v /tmp:/tmp ruimo/lightocr tesseract /tmp/form000.png
3.14159265
正しく認識されている。もっともこれは、tesseractで-psm 7を指定しても正しく認識できる。
$ tesseract form000.png stdout -psm 7 digits
3.14159265
Google Cloud Visionでもok。
お次は、イメージ切り抜きの際にズレて右側の罫線が入ってしまったケース。
普通にtesseractで認識してみる。
$ tesseract form001.png stdout -psm 7 digits
3.141592651
罫線部分が1と認識されてしまう。無理もない。今回のOCRで処理してみる。
$ docker run -it --rm -v /tmp:/tmp ruimo/lightocr tesseract /tmp/form001.png
3.14159265
等幅フォントを仮定して切り離した後に、幅が極端に小さなものは捨てるためきちんと認識できている。Google Cloud Visionだと、正しく認識できている。さすがだ。
次は罫線がもっと数字に寄ってしまったケース。
普通にtesseractで認識すると、
$ tesseract form003.png stdout -psm 7 digits
3.14159263
最後の5が3と誤認識されていることが分かる。今回のOCRを使うと、
$ docker run -it --rm -v /tmp:/tmp ruimo/lightocr tesseract /tmp/form003.png
3.14159265
正しく認識できた。等幅フォントを仮定して切り取るため、罫線がうまく削除できたのだと思われる。Google Cloud Visionだと、
やはり正しく認識できていてさすがだ。次は下に罫線が残ってしまったケース。
普通にtesseractを使うと、
$ tesseract form004.png stdout -psm 7 digits
1 0 .
全然ダメになってしまった。今回のOCRだと、
$ docker run -it --rm -v /tmp:/tmp ruimo/lightocr tesseract /tmp/form004.png
3 11159255
幾分改善するが、やはり誤読が見られる。もっとも横方向の罫線については、黒成分が極端に高いものを除外することで、除去できるかもしれない。Google Cloud Visionだと、
やはりきちんと認識されている。ここまではGoogle Cloud Visionの圧勝だ。次に印字が不鮮明なケースを検証してみる。ドット・インパクト・プリンタの場合、良く一部が不鮮明になるケースがある。これは6の下部が消えてしまった例。
tesseractで認識してみる。
$ tesseract form005.png stdout -psm 7 digits
3.14159255
誤読してしまっている。今回のOCRでは、
$ docker run -it --rm -v /tmp:/tmp ruimo/lightocr tesseract /tmp/form005.png
3.14159265
正しく認識された。1文字として認識する場合には精度が上がるようだ。Google Cloud Visionでは、
やはり圧倒的な強さを見せつけている。最後に全体にもっと不鮮明な上に罫線がカブっているケースを見てみる。
tesseractで普通に認識すると、
$ tesseract form006.png stdout -psm 7 digits
70001393652
最後の2桁を誤読しているが、左の罫線による悪影響は出ていなかった。今回のOCRを試してみる。
$ docker run -it --rm -v /tmp:/tmp ruimo/lightocr tesseract /tmp/form006.png
7000139369
正しく認識できた。Google Cloud Visionでは、
Google先生、全勝はならず。tesseractは、ホワイト・リストで「数字しかない」という情報を与えることができる(引数のdigits)が、Google Cloud Visionはそういう指定が無く、言語の指定しかできないので印字が不鮮明な場合は、tesseractの方が良い結果が得られる場合もあるようだ。
というわけで、割と良い結果が得られたので満足。
24番は一転して小規模となり2楽章しかない。ここから27番あたりまでは、あまり規模の大きなものは書かれておらず、小規模指向になっている。
最初に夢見るような序奏が置かれている。
最初の符点が曲全体で繰り返し使われる。
この音型も曲全体で使われる。
この曲では、初期の頃と同じように色々なテーマが出てくる。
ここの右手は音型は伴奏のようだが、展開部で使われる。
展開部は短調で始まる。展開部は非常に短かい。
呈示部の2つの音型が組み合わされる。
再現部。この曲は最後まで達した後、展開部から繰り返しが行われるという珍しい構成がとられている。
楽譜引用はヘンレ版から。
Apple Musicの方はこちらから。
冬休みの自由研究は、OCRを作ってみることにした。世間一般のOCRは、キャプチャに出てくるような文字をいかに高精度に認識できるかに関心がある感じだけど、ビジネスへの適用だと、以下みたいな限定的な条件を課すかわりにより精度を上げられた方がメリットがあるように考えた。
- 1行分の数字列を認識する。
- 認識するのは、手書きなどは除外でマシン・プリントに限定。
- 基本は数字列のみが認識できれば良い。
- 文字は、等幅フォントを仮定して良い。
実装は、まずイメージ処理で数字列から各数字を分離する。まずy方向で数字列がある領域を探す。これは黒い部分の濃度が高い部分が、しきい値を超えて固まっている部分を抜き出すことで行う。
次にx方向で数字ごとに分離する。これは、各数字の高さに対する幅の比率に仮定(今回は、50-90%)を置くことで、その範囲で各数字の分離を試みて分離境界位置の黒成分が最も少ないところで切り取る。等幅である仮定を置くことで、より高い精度で分離が可能になる。
あとは、ニューラルネットで学習したモデルを使って、分離した各数字を判定する。今回はdeepLerning4jを使用した。教師データは、とりあえずMNISTを使用した。MNISTは手書き文字なので、印字フォントだとあまり精度が出なさそうだけど、とりあえず今回は実装時間を優先。
サンプル・コードは、Dockerizeしてdocker hubでビルドしたので、Dockerがあれば簡単に試すことができる。コードは、数字の分離だけを行う機能と、ocrまで行う機能を作成した。ソースはこちら。
数字の分離は以下で行える。
$ docker run -it --rm -v /tmp:/tmp ruimo/lightocr split /tmp/005.png
引数に、pngで処理したいイメージファイルを指定する。Dockerコンテナ内から見えるようにボリューム指定が必要(-v /tmp:/tmp)。例えば以下のようなイメージを用意した場合、
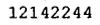
/tmp/005の下に、以下のイメージが生成される。
/tmp/005/000.png: 
/tmp/005/001.png: 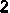
/tmp/005/002.png: 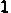
/tmp/005/003.png: 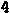
/tmp/005/004.png: 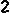
/tmp/005/005.png: 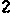
/tmp/005/006.png: 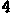
/tmp/005/007.png: 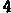
OCRの実行は以下で行える。
$ docker run -it --rm -v /tmp:/tmp ruimo/lightocr ocr /tmp/005.png
引数に、pngで処理したいイメージファイルを指定する。Docker内から見えるようにボリューム指定が必要(-v /tmp:/tmp)。例えば上記のイメージを用意した場合、
/tmp/005.txtにOCRで認識した数字列が生成される。
32392242
毎回、MNISTをダウンロードして学習してから認識に入るのでそれなりに時間がかる。
やはりMNISTが教師データなので精度はいまいちだが、印字文字を集めて学習すれば良くあるMNISTによる認識よりも高い精度が得られそうだ。また、業務で使用するプリンタが限定できるなら、そのプリンタに特化した教師データを集めれば、より高い精度が得られるはず。
教師データ揃えて、学習や認識をRESTで行えるところまでやりたかったけど、今回は時間切れ。
第2楽章は変奏曲。
緊張感の高い2つの楽章にはさまれた、この楽章はとても暖かなテーマが変奏される。
変奏1。
変奏2
変奏3
最初のテーマに戻る。
不気味な分散和音の後、attaccaで第3楽章に流れ込む。
出だしに和音の強打があり、ppでテーマが始まり強烈な緊張感を与える。
右手で最初のテーマが奏される中で、左手側に新たな萌芽が見えてくる。
曲は、最初のテーマがこれでもかと言うほど使われる。
展開部。
右手に新たなリズムが現れて盛り上がる。
再現部の後に、最後にプレストが配置されている。最初は新たなテーマが奏される。
しかしすぐに最初のテーマの展開となる。
テーマの展開の後に、アルペジオに流れ込んで劇的に終了する。
楽譜引用はヘンレ版。
Apple Musicの方はこちら。
Facebookの広告に表示されたんだけど、なんか怪しげな部品テスタを買ってみた。いや今回ばかりは、Facebookの広告エンジンすげ〜と思った。自分が興味を持ちそうのものドンピシャ。
何せ日本への送料無料で$9.99。これならハズレ品だとしても、まぁお正月の福袋を買ったと思えばいいわけで。Order入れたのが去年の12/25で、まぁ2週間くらいかかるんだろうなと思ったら1/2に届き、まさに福袋感覚。
すっかりマイナーとなった006Pが必要なのでコンビニ行ったら、まさかの500円超え。秋月に行けば100円で買えることを知っている身としては、さすがに手を出せず、ジャンク箱をあさったらテスターのおまけで付いて来たものを発見。
ケースはアクリルで、バラバラになるので、自分で組み立ててネジ止めしなきゃいけないくて、ちょっと面倒。これ電池交換の度にバラバラになっちゃうのでやっかいだ。まぁ、考えてみると天板以外は接合部を塩化メチレン流し込んで止めちゃえばいいのかな。
というわけで、手持ちの部品を適当に見繕ってテストしてみた。まずは抵抗から。抵抗値が低い方で0.68Ω
ちゃんと測定できている。抵抗測定だと電圧降下で見るだろうから、低抵抗をきちんと測るのは大変そうなのに優秀だ。次に高抵抗側。
5.6MΩ。ここまで測定できればok問題無し。次はコンデンサ。
まずは低容量の方で22pF。さすがに、ここまで小さいと無理か。
47pFならokなので、下限は思ったより低い。次は高容量側。
0.1μFも大丈夫。日本人的には、このnFってピンと来ないのよね。仕方無いけど。
100μFもok。
なんと470μFもok。
3300μFもok。ただ、高容量になると測定に時間がかかるようになる(それでも5秒くらいか)。コンデンサ測定ではESRも表示されるのが良い。
コイル(マイクロ・インダクタ)も測定できた。
水晶振動子は無理。はい。分かってました。
シリコン・ダイオード。Vfが表示されるのが良い。
こういうダイオード・アレイもちゃんと表示されてすごい。
それならばとショットキー・バリア・ダイオード。ちゃんとVfが0.6V切っているのが分かって楽しい。って、上のダイオード・アレイもVf見るとショットキー・バリア・ダイオードだったみたい。
2SC1815は期待通り。HFEやVfも表示される。hFEという先頭だけ小文字の表記は何なんだろ。多分表示値は直流電流増幅率の方だと思われる。
MOS FETもちゃんと表示される!。ゲート容量が表示されるので、高速スイッチングが必要な時には参考になるかも。
LEDのようなVfの大きなデバイスもok。LEDの極性、普通のテスタで測るの困難なので、基盤から外したLED(リードを切ってしまって長さから極性が分からないもの)は助かりそう。
というわけで、予想外に優秀でいい意味で期待を裏切られた。測定時間も2-3秒で待たされないし、ゼロ・プレッーシャ・ソケットを使っている点も良い。テスタで部品を測定するのって、テスタ棒を確実に部品に当てるのが結構辛いのだよね。10秒くらい放置すると、オート・パワーオフになるが、再測定は普通にボタンを押せばすぐに可能で、起動時間とかは不要だった。あとは、電池がどのくらいもつのか。このゼロプレッシャ・ソケットなのだけど、全端子が使えるわけではなくて、左の3端子のみが有効みたい。抵抗みたいにピン間離れているデバイス用に、右側の端子は左から3番目の端子とショートした状態でいいんじゃないかな。まぁ、これくらいなら自分で改造しちゃえばいいのだけど。
いや本当にすごい。液晶パネルに、マイクロコントローラ、ゼロ・プレッシャ・ソケット。これ部品代だけで$9.99超えてない? しかも、良くできた測定プログラム。とても楽しませていだだきました。
最も有名なソナタの1つ。第一楽章は基本となる幾つかの音型が何度も使用される、お馴染のパターン。最初は独特なリズムを持った不気味なテーマで始まる。
その後にトリルを伴ったテーマ。この音型は、第2楽章の最初のテーマに似ている。
そして、運命の動機。このテーマも曲全体で何度も用いられる。
長調になって暖かなテーマが現れるが、実際は最初のテーマの変形。
16分音符の激しいテーマ。
展開部。最初のテーマが徹底的に展開される。
左手の八分音符の連打の上に最初のテーマが再現され、独特の緊張感を与える。
ここからアルペジオ主体で自由に激情がひとしきり表現される。
ここからアレグロに戻り、ffで運命の動機が奏されて、楽章の最後を飾る。
最初のテーマが繰り返されて静かに終わる。
楽譜引用はヘンレ版。
Apple Musicの方はこちら。